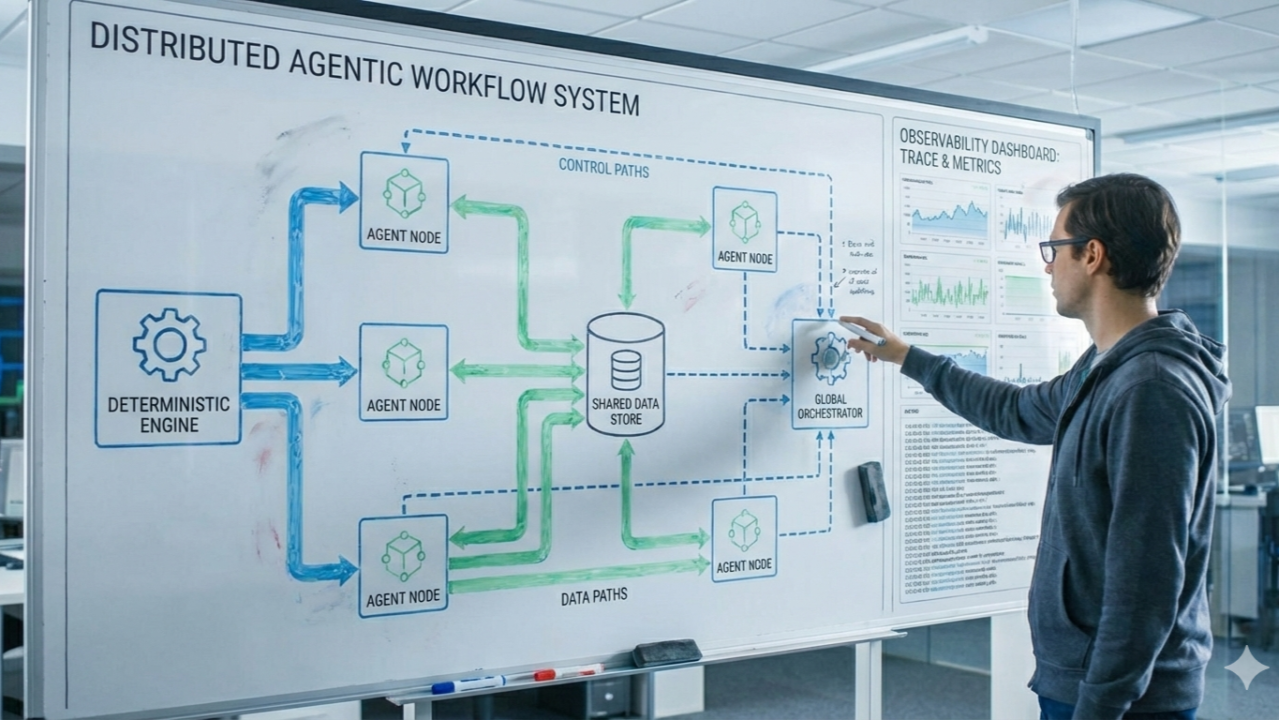
Everyone is building “agents.” Very few teams are building agent systems that are deterministic, debuggable, and production-safe.
If your agentic platform can’t answer:
- what happened,
- why it happened,
- which version made the decision,
- and how to replay it safely,
then it’s not production-ready yet.
I’ve been implementing an agentic workflow architecture with one core principle: treat agents like distributed systems, not just prompts.
1) Deterministic by design (not by hope)
A reliable agent workflow should produce stable outcomes from:
- event input,
- current state snapshot,
- pinned control versions.
That means:
- immutable version pins for policy/workflow/agent bundles,
- idempotency keys for every external side effect,
- explicit retries and DLQ/replay paths,
- deterministic state transitions in orchestration.
Determinism is what makes debugging possible and rollback meaningful.
2) Clear control plane vs data plane separation
A common anti-pattern is mixing governance with runtime execution.
A cleaner model:
Control Plane
- policy definitions and capability rules
- workflow templates and versioning
- model/provider configuration
- rollout and rollback policy
- tenant-level config and quotas
Data Plane
- event ingestion and normalization
- orchestration and task routing
- agent execution
- decision aggregation
- action dispatch and replay
The control plane decides what is allowed. The data plane decides what happened right now.
3) Observability is the product, not a bolt-on
Agent platforms fail silently unless you trace everything.
Minimum observability contract:
- trace correlation keys: tenantid, eventid, orchestrationid, runid
- span-level lifecycle across ingestion → orchestration → agent run → decision → dispatch
- structured logs with redaction
- metrics for latency, retries, DLQ rate, and circuit-open ratio
- replay audit trail (who replayed, why, and outcome)
If you can’t replay and explain, you can’t govern.
4) Production hardening patterns that matter
In practice, these patterns matter more than model tweaks:
- circuit breakers on model/provider calls
- fallback provider chain with explicit telemetry
- strict idempotency across dispatcher boundaries
- schema-versioned events
- canary + shadow rollout before promotion
Even “small” parser issues can create user-facing failures at scale. For example: long JSON-like model responses can degrade into useless outputs unless normalization logic is robust and regression-tested.
5) A practical implementation path
You don’t need to boil the ocean.
Phase 1
- canonical event envelope
- trace + idempotency baseline
- single orchestrator with deterministic transitions
Phase 2
- split agent-runner and decision-aggregator
- introduce decision read model
Phase 3
- add action-dispatcher hardening, retry, DLQ, replay tooling
- operator dashboard for auditability
Phase 4
- progressive rollout governance (canary/shadow/rollback)
- optional RL feedback loop and policy optimization
6) Final takeaway
The future isn’t “one super-agent.” It’s well-governed agent systems with deterministic execution, strong observability, and strict plane separation.
If we want agentic systems in production, we need to engineer them like resilient platforms.