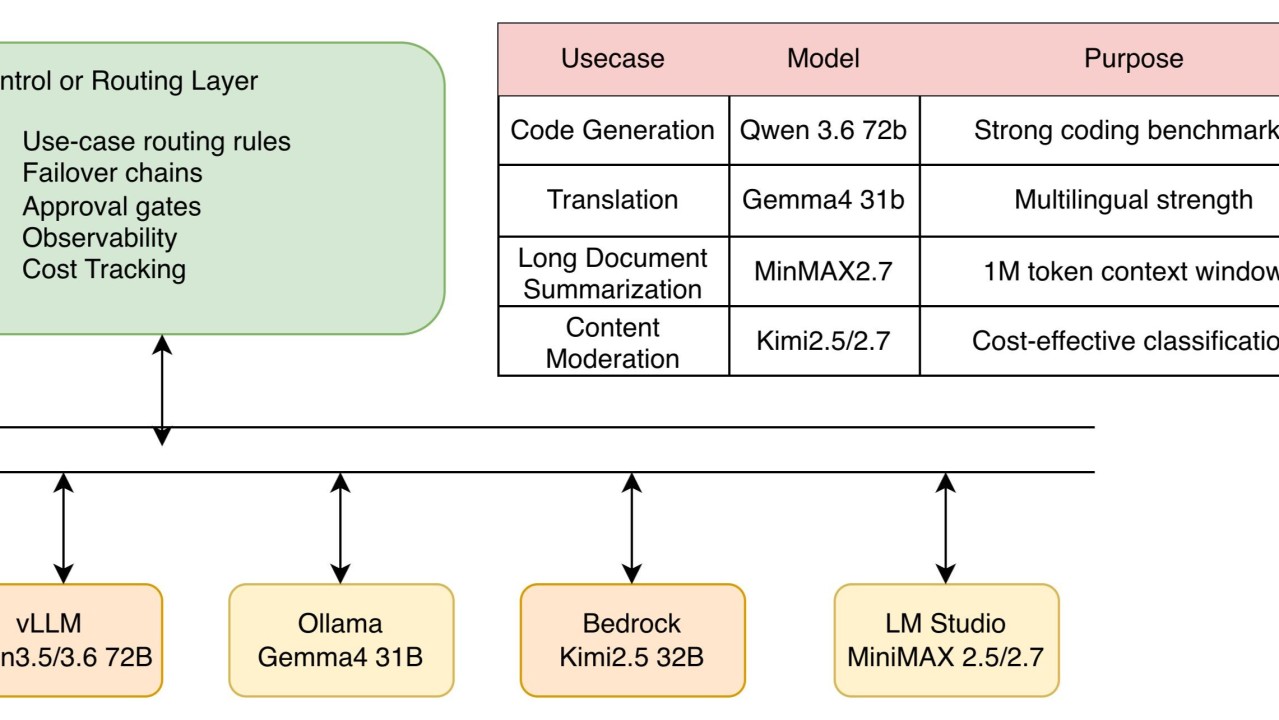
Organisations are increasingly running multiple open-source models (Qwen, Gemma, Kimi, MiniMax, Llama, DeepSeek) alongside managed APIs. It's the control layer that decides which model handles which request, what happens when one fails, and when a human needs to step in.
Here is an architecture pattern that works.
Three Layers
- Inference layer — GPU servers running model weights (vLLM, Ollama, TGI) or managed endpoints (Bedrock, Vertex AI)
- Control layer — routing logic, failover, approval workflows, and session management
- Client layer — web apps, mobile apps, internal tools consuming the unified API
Step 1: Serve the Models
Each open-source model needs a serving runtime that exposes an OpenAI-compatible /v1/chat/completions endpoint. This lets the control layer treat every model uniformly.
- vLLM — production-grade, supports tensor parallelism across multiple GPUs. Best for large models (Qwen 72B, DeepSeek 67B).
- Ollama — simple single-node setup. Good for development and smaller models.
- LM Studio — desktop GUI with local server. Useful for prototyping.
- Amazon Bedrock / Vertex AI — managed hosting. No GPU management, pay-per-token. Hosts Qwen, Kimi, Llama, and others.
The key decision: self-hosted vs. managed is not binary. The strongest production setups are hybrid — run your primary models on your own GPUs for cost and privacy, keep managed endpoints as fallbacks.
Step 2: Define Routing Rules
A. Primary + Fallback Chain
Every request goes to Model A. If it fails (timeout, overloaded, OOM), try Model B, then C:
primary: qwen-72b
fallbacks: [gemma, kimi-large, bedrock/llama]
This is the most common pattern. It gives you resilience without complexity.
B. Use-Case Routing
Different tasks go to different models based on request type:
- Code generation → qwen-72b (best code quality)
- Summarisation → gemma-27b (fast, cost-effective)
- Classification → gemma-9b (low latency)
- Legal/compliance → kimi-large (long context)
Route at the application layer — tag each request with its use case, and the control layer selects the model.
C. Per-Tenant / Per-Channel Routing
enterprise-tier → qwen3.6-72b (dedicated GPU)
standard-tier → gemma4-31b (shared pool)
internal-tools → ollama/local (free)
D. User-Switchable
Let power users pick their model at runtime. Expose an allowlist of approved models so users can trade off speed vs. quality without leaving your platform.
Step 3: Implement Failover Properly
Naive failover (retry on any error) wastes GPU cycles. A good failover system distinguishes:
- Retriable errors (rate limit, temporary overload): retry same model with backoff
- Failover errors (model crashed, auth expired, context too long): advance to next model in the chain
- Non-retriable errors (invalid request, content policy): fail fast, don't waste other models' capacity
Additional production patterns:
- Auth rotation — if you have multiple API keys for the same provider, rotate through them before failing over to a different model
- Session stickiness — pin a user's session to one model/key to keep provider-side KV caches warm (dramatically reduces latency for multi-turn conversations)
- Cooldown tracking — when a model returns a rate limit with a
retry-afterheader, mark it as cooling down and skip it for the specified duration
Step 4: Add Human-in-the-Loop
A. Approval Gates
Define which actions require human sign-off before execution:
if action = "send_email" OR action = "modify_database":
HOLD for human approval
notify reviewer via Slack/Teams/email
execute only after explicit approval
B. Confidence-Based Escalation
- Run request through Model A (Qwen)
- Run same request through Model B (Gemma)
- Compare outputs
- If outputs diverge significantly → escalate to human
- If aligned → deliver with high-confidence tag
This dual-model verification pattern is especially valuable for compliance, legal review, and medical content.
C. Standing Authorization with Boundaries
Instead of approving every action, define what the system can do autonomously:
AUTHORIZED:
- Classify incoming support tickets
- Draft response using the knowledge base
- Route to the correct department
REQUIRES HUMAN APPROVAL:
- Issue refunds over £100
- Escalate to legal
- Respond to press/media inquiries
ESCALATION TRIGGERS:
- Customer sentiment score < 0.3
- Request mentions litigation
- Model confidence < threshold
This "standing orders" pattern lets the system handle 80–90% of volume autonomously while routing edge cases to humans.
Step 5: Infrastructure on AWS
Recommended deployment:
- g5.xlarge (1× A10G, 24 GB) — models up to 13B parameters
- g5.12xlarge (4× A10G, 96 GB) — models up to 70B
- p4d.24xlarge — very large models (70B+) at production throughput
- Amazon Bedrock — fallback for when spot capacity is reclaimed
Cost optimisation:
- Use Spot Instances for non-critical inference workloads (50–70% savings)
- Keep a Bedrock fallback for when spot capacity is reclaimed
- Set
cost: 0for self-hosted models in your routing config so the control layer prefers them over pay-per-token APIs
Key Takeaways
- Standardise on OpenAI-compatible endpoints. Whether you use vLLM, Ollama, or Bedrock, expose
/v1/chat/completions. This makes your control layer provider-agnostic. - Hybrid > pure self-hosted. Run your primary workload on your own GPUs. Keep managed APIs as fallbacks. This gives you cost control + resilience.
- Routing is a product decision, not just infrastructure. Which model handles which use case should be configurable by product teams, not hardcoded by engineers.
- Failover needs intelligence. Don't just retry blindly. Classify errors, rotate credentials, respect cooldowns, and pin sessions.
- Human-in-the-loop is not optional for production. Define clear boundaries between autonomous operation and human review. Use confidence thresholds and dual-model verification for high-stakes outputs.
The models are commoditising. The control layer is the differentiator.